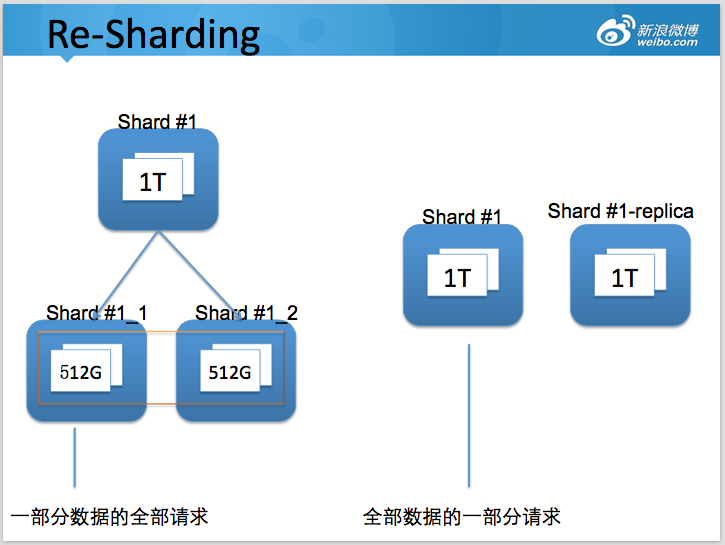
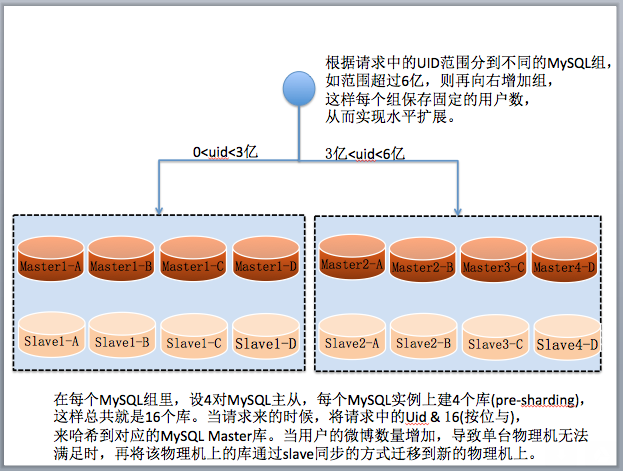
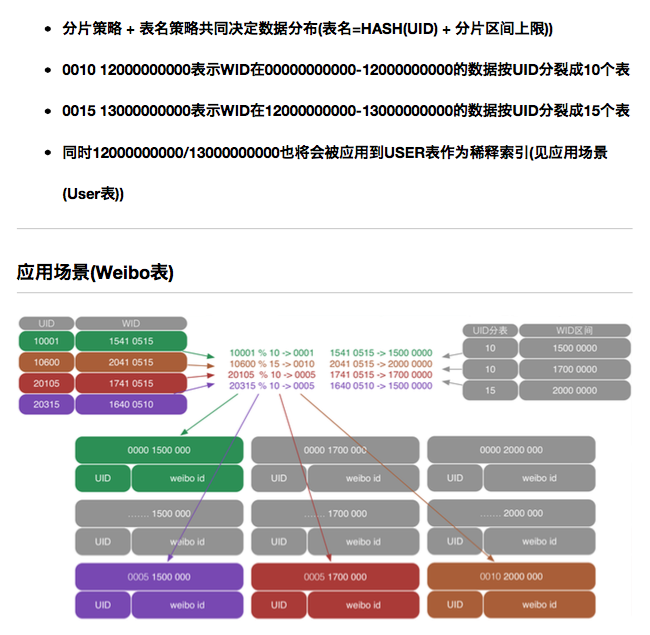
作者注:本文发表于 2015 年 12 月 24 日。
平安夜在中国是个跟宗教无关的节日,即使不忙的人在这晚也需要假装日程很紧。中关村的基督教堂依旧像往年一样人头涌涌;路边的餐厅很多提前下班了,那些年轻的服务员也需要在这个夜晚去释放他们的青春。而在另外一边,在互联网的虚拟世界里,一大群工程师正在 2015 年平安夜通过网络参与一个 Hadoop 及 HBase 年度回顾的「高可用架构」群直播分享活动。
在线直播是最近在很多垂直社区流行的一种分享方式,讲师通过社交、通讯或在线教育 app,以语音或者图文的方式向所有在线收听的用户传授知识,而听课的人群可以利用移动 app 的优势,随时随地参与学习及交流。
在罗辑思维中提到
在一个信息泛滥的时代,信息本身零价值,信息渠道也不再值钱。传播的枢纽是魅力人格体。
世界上没有那么多魅力人格体,但每个领域都不缺意见领袖。在 IT 领域尤其是技术领域,知识的升级迭代速度非常快,因此从业群体需要比其他行业更多更快的学习新知识及了解新资讯。因此有大量人群被这些垂直领域的意见领袖聚集在群、自媒体等社交渠道周围。比如上面提到群直播,就是一些活跃在前沿的讲师给大家讲授业界最前沿的热点技术内容,参与人员也会通过群提供的二维码给讲师打赏,在群中通常戏称为“交学费”。
而在线下,也有另外一些不同的新的玩法。极客邦科技(InfoQ 中国背后的公司)今年成立了一个技术人学习组织 EGO,会员主要以公司技术负责人为主。Tim 由于也是其中的会员之一,因此有机会结识了很多新的会员。这些加入会员也是在自己的职业生涯某些方面存在困惑,公司的工作太忙,网上的信息太庞杂,去校园进修又不太现实,因此其实很缺乏高效的线下学习途径。
Tim 在与这些会员交流的过程中,发现大部分人在他们相关的领域非常优秀,也慢慢了解他们所属公司最近几年的发展历程,了解他们所在的不同行业的发展情况,也了解到他们在不同领域的奋斗、成长与得失。Tim 也很喜欢这种交流的过程,一方面,与这些行业优秀的技术人一起可以快速学到他们身上的优点及特长,同时也可以通过他们了解到许多以前不了解的领域。
一次一个会员问了 Tim 一个非常好的问题,“你最近在这个组织得到的最大收获是什么?”
对于 Tim 而言,如上所述,最大的收获是跟不同会员的深度交流,学习会员做事的方法与理念,了解他们对于行业方向的判断、以及对于技术的态度及选择。
这也是每个人加入一个学习组织或者线上群体经常思考的问题,为什么要来到这里?你在这里一段时间的收获是什么?
在论坛中,我们的主要诉求是内容及人的发现,内容方面包括发现有价值、值得收藏的内容,同时通过内容发现背后有思想的人,通过在社区交流观点,用户之间产生互动,从而在贡献内容之余彼此熟悉,形成社区。所以,在一个论坛一年的收获通常是发现了有价值的内容,结识了值得结识的朋友。
在移动时代,传统的论坛方式慢慢被其他更移动及社交化的方式代替,用户更多时间停留在社交及通讯的 app 中。Tim 今年也创建了一系列「高可用架构」群,主要关注互联网架构领域的内容传播,虽然不如传统的论坛那么正式及严谨,但慢慢也聚集了一大批各个公司的技术群体,一起讨论各种技术及非技术的话题。
群直播分享相对与传统的技术会议及技术媒体,非常不正式,目前也算不上主流的交流或学习方式。一篇采访张泉灵的采访中,提到她眼中新接触的一些新的互联网产品印象。
傅盛给我看他的一个投资,叫“小余老师说”,做视频的项目,当时在优酷上,很早期一集就有一百多万点击量。傅盛得意地跟我说,你看我投了一个特别有特质的孩子。我是做媒体的,视频看了很多,当时我特别不屑一顾:它的LOGO和背景完全一个颜色,“小余老师说”五个行草不规则叠在同样颜色的花色背景上,节目上的小余老师背后是一个斑马纹的欧式椅子,他人又不高,椅背整个呼在后面。看完我完全疯掉了,说这东西凭什么?
傅盛跟我说,其实你要理解的事情是现象及规律——一个东西在互联网上,有一百万的点击,而且能持续,就一定不只凭运气。你的重点不是想凭什么是他,而是你要想为什么是他。想明白之后,你还要理解,互联网对某样东西的认可,是带着资本和传播势能的。
当时我找了团队里的90后,说把B站最火的视频统统给我看一遍。我一边看一边崩溃,一边还要理解:视频有三层弹幕,你根本不知道后面是什么,三层弹幕密密麻麻的,一个字都看不清,还唱那样的歌。但你要慢慢理解这种亚文化的背后是什么,这些用户是谁。
很多基于社交及通讯软件新的学习方式也是如此,这些方式可能充满了噪音,学习效率也存在问题,手机上浏览及参与也不便,产出也不稳定,质量良莠不齐,但无法逃避的问题是,我们的大部分时间停留在此。在这里,一旦有优质的内容,就会有更快的速度传遍这个圈子的每一个角落。这也是为什么非常多朋友选择这种方式并帮助一起去进化它。
有人说,一个男人变老的两大标志是不断后退的发际线和不断增长的腰围。
其实,一个人真正变老的标志是,他觉得人生一眼望得到投,不会再有改变。
于是放弃了学习,放弃了提升自己。
「你一年的 8760 小时」