由于Google Wave还未上线,目前了解Google Wave最佳方式是观看youtube上的演示视频或者官方Lars Rasmussen写的Went Walkabout. Brought back Google Wave。本文重点从技术角度谈下对Wave体会。(注意此文部分链接由于GFW原因国内不能访问,并非写错地址。)
一、总体概述
Google Wave它并不仅是一个前端的产品,它的整个技术可以概括为3P组成
Product
http://wave.google.com/ Product可以理解成Wave前端,基于HTML 5构建,从演示看可以运行在 Google Chrome, Firefox, Safari上。
Platform
http://code.google.com/apis/wave/ Google Wave的开发平台,目前可以进行以下类别的开发
- Extensions: 构建扩展,Google也称它为robot,比如在视频演示中的拼写检查、Google search集成、Twitter Wave扩展等。可以将各种互联网应用导入以wave document方式呈现及交互。
- Embed: 嵌入,可以将wave嵌入到web应用,嵌入的Wave具备wave的基本特性,比如显示实时更改。视频中演示了将wave嵌入到blogger.com中作为一篇文章。
Protocol
http://www.waveprotocol.org/ 目前的Wave协议为基于XMPP core的一个扩展,但是它也只是一个扩展而已,并没要求双方服务器完全支持XMPP特性,就是Wave服务器并不需要支持XMPP的presence, message协议。(XMPP与Wave相关介绍可参看我的另外一篇文章Google Wave与XMPP)
总的说来,Google Wave整个体系将会是开源的,就是说每个公司都可以架构自己的服务器及前端,如果拿邮件系统来比喻的话,Product等同邮件前端webmail, Platform就是webmail各种插件,protocol就是SMTP/POP3/IMAP协议。
二、HTML 5 及 Google Web Toolkit

上节介绍Product即前端是基于Google Web Toolkit来实现,印象深刻的有几点
- Google Web Toolkit是用Java代码来直接写前端,并不需要直接编写JavaScript,可能会影响以后前端的开发方式。有点类似n年前当VB/Delphi出来之后, 程序员基本就放弃了使用Windows SDK去写普通界面
- 一次编写,跨浏览器,可运行在Chrome, Firefox, Safari上
- 特性丰富,在浏览器里面完成了很多一般认为是不可能在浏览器完成的任务,再看完演示之后,你可能不敢相信它是通过浏览器完成的。图片可以直接从桌面拉进conversation, 由于需要网络传输,对方会看到逐渐加载新拉进的图片,但也几乎是实时的。(由于HTML 5暂不支持drag and drop,暂时通过Google Gears完成。)
- Google Web Toolkit同时支持iPhone, Android两种Mobile终端。据Lars Rasmussen介绍的经验,使用GWT增加Mobile支持只需要增加5%的开发工作量。
- 因此Tim觉得browser based也是手机应用的一个方向,而不是写无法跨平台的各种终端本地native应用。一个证明就是Google latitude for iPhone 已经不考虑native实现了,而是采用支持HTML 5版本的Safari。同时Android平台也在尽量让浏览器支持这一特性,TechCrunch这篇文章介绍如下
Thanks to HTML 5, Safari will be able to access a user’s location information and Latitude will be able to access that as well (provided the user gives permission). This will put it on par with what Google is doing in its browser for Android. (原文)
- 那大部分Mobile应用,比如SNS平台,SNS扩展应用,电子商务应用(如淘宝)也完全可以基于浏览器去实现。
三、Wave是一个Realtime应用平台
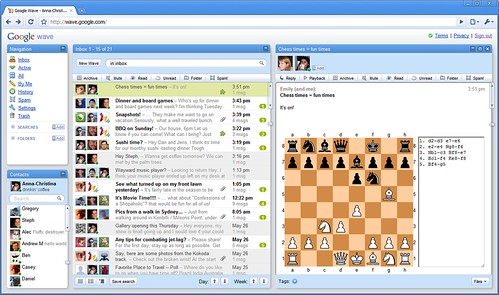
由于传统场景比如多人实时编辑相关介绍已经较多,这里介绍些不同的思路,先看两个图片
国际象棋
数独游戏
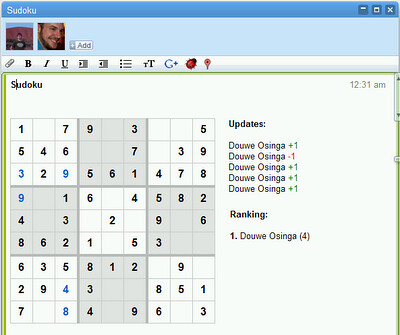
这是一个运行在Wave中的Gadgets,需要说明的有
- 只是2个普通的Gadgets, 但是Wave让它具备了多人参与及realtime显示的特性。
- Gadget本身不需要考虑为Wave作任何改造
因此个人认为这种技术可以更扩展应用在SNS扩展平台,Web Game等领域,软件的实时通讯功能由平台来提供,软件开发将会更简单,更容易实现大规模的部署及运营。