上周看了Linux的进程与线程,对操作系统的底层有了更进一步的一些了解。我同时用Linux内核设计与实现和Solaris内核结构两本书对比着看,这样更容易产生对比和引发思考。现代操作系统很多思路都是相同的,比如抢占式的多线程及内核、虚拟内存管理等方面。但另外一方面还是有很多差异。在了解锁和同步之前,原子操作是所有一切底层实现的基础。
原子操作Atomic
通常操作系统和硬件都提供特性,可以对一个字节进行原子操作的的读写,并且通常在此基础上来实现更高级的锁特性。
原子操作通常针对int或bit类型的数据,但是Linux并不能直接对int进行原子操作,而只能通过atomic_t的数据结构来进行。目前了解到的原因有两个。
一是在老的Linux版本,atomic_t实际只有24位长,低8位用来做锁,如下图所示。这是由于Linux是一个跨平台的实现,可以运行在多种 CPU上,有些类型的CPU比如SPARC并没有原生的atomic指令支持,所以只能在32位int使用8位来做同步锁,避免多个线程同时访问。(最新版SPARC实现已经突破此限制)
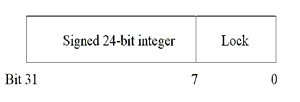
另外一个原因是避免atomic_t传递到程序其他地方进行操作修改等。强制使用atomic_t,则避免被不恰当的误用。
atomic_t my_counter = ATOMIC_INIT(0);
val = atomic_read( &my_counter );
atomic_add( 1, &my_counter );
atomic_inc( &my_counter );
atomic_sub( 1, &my_counter );
atomic_dec( &my_counter );
Solaris的实现是基于test-and-set的指令,并且该指令为原子操作。比如Solaris的实现在SPARC上是基于ldstub和cas指令,在x86上用的是cmpxchg指令。但是Linux似乎直接用的add指令。
OpenSolaris i386的实现
movl 4(%esp), %edx / %edx = target address
movl (%edx), %eax / %eax = old value
1:
leal 1(%eax), %ecx / %ecx = new value
lock
cmpxchgl %ecx, (%edx) / try to stick it in
jne 1b
movl %ecx, %eax / return new value
ret
在Linux源代码asm_i386/atomic.h中
static __inline__ void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__(
LOCK "addl %1,%0"
:"=m" (v->counter)
:"ir" (i), "m" (v->counter));
}
锁的类型
如果锁被占用,尝试获取锁的线程进入busy-wait状态,即CPU不停的循环检查锁是否可用。自旋锁适合占用锁非常短的场合,避免等待锁的线程sleep而带来的CPU两个context switch的开销。
如果锁被占用,尝试获取锁的线程进入sleep状态,CPU切换到别的线程。当锁释放之后,系统会自动唤醒sleep的线程。信号量适合对锁占用较长时间的场合。
顾名思义,自适应锁就是上面两种的结合。当线程尝试申请锁,会自动根据拥有锁的线程繁忙或sleep来选择是busy wait还是sleep。这种锁只有Solaris内核提供,Linux上未见有相关描述。
几种锁的性能比较(Windows操作系统下,第一种类似atomic_inc, 2,3类似spinlock, 4,5类似semaphore)

(图片来源:Intel Software Network)
Java synchronization
再理论联系实际一下,看Java中的锁底层如何实现的。这篇关于JVM的Thin Lock, Fat Lock, SPIN Lock与Tasuki Lock中讲到Java synchronization实际上也是一种自适应锁。
于是,JVM早期版本的做法是,如果T1, T2,T3,T4…产生线程竞争,则T1通过CAS获得锁(此时是Thin Lock方式),如果T1在CAS期间获得锁,则T2,T3进入SPIN状态直到T1释放锁;而第二个获得锁的线程,比如T2,会将锁升级(Inflation)为Fat Lock,于是,以后尝试获得锁的线程都使用Mutex方式获得锁。
Java AtomicInteger的实现,似乎和Solaris的实现非常类似,也是一个busy wait的方式
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
*
* @param expect the expected value
* @param update the new value
* @return true if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(int expect, int update) {
// unsafe.compareAndSwapInt是用本地代码实现
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
Solaris
感觉OpenSolaris在很多地方要比Linux优秀,Solaris在理论设计和实践上都非常优雅,而Linux内核很多地方似乎更偏工程实践方向一些。另外Solaris用来做学习操作系统更合适,它的mdb几乎无所不能。
我在VirtualBox虚拟机上安装了OpenSolaris,非常容易安装,使用这个Minimal OpenSolaris Appliance OVF image for VirtualBox 2.2 简易方法,安装一个没有gui的版本,大约3分钟以内就可以装好。OpenSolaris安装软件和Ubuntu一样方便,使用 pkg install SUNWxxx 的命令,比如 pkg install SUNWcurl
