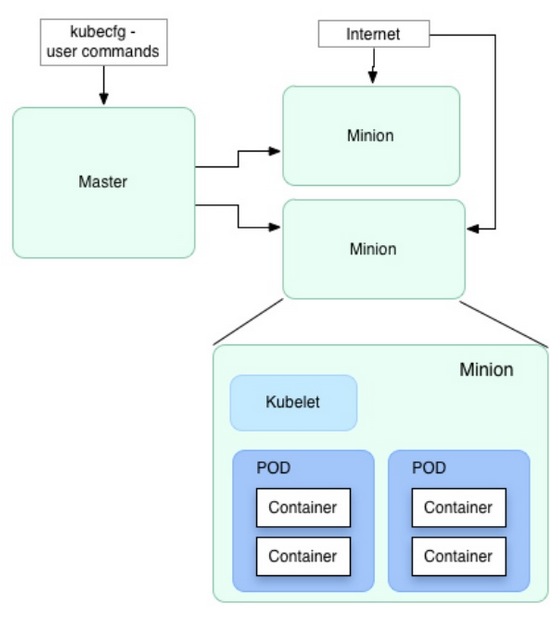
Kubernetes是Google开源的容器集群管理系统。前几天写的 分布式服务框架的4项特性 中提到一个良好的分布式服务框架需要实现
服务的配置管理。包括服务发现、负载均衡及服务依赖管理。
服务之间的调度及生命周期管理。
由于Kubernetes包含了上述部分特性,加上最近Google新推出的Container Engine也是基于Kubernetes基础上实现,因此最近对Kubernetes进行了一些尝试与体验。
运行环境
Kubernetes目前处于一个快速迭代的阶段,同时它的相关生态圈(比如docker,etcd)也在快速发展,这也意味没有适合新手使用非常顺畅的版本,网上的各种文档(也包括官方文档)和当前最新的发布版会有不同程度滞后或不适用的情况,因此在使用时可能会碰到各种细节的障碍,而且这些新版本碰到的问题,很有可能在网上也搜索不到解决方案。
Kubernetes设计上并未绑定Google Cloud平台,但由于以上原因,为了减少不必要的障碍,初次尝试建议使用GCE作为运行环境(尽管GCE是一个需要收费的环境)。默认的cluster启动脚本会创建5个GCE instance,测试完需要自己及时主动删除。为了避免浪费,可以将minions减少,同时instance类型选择f1-micro。费用方面一个f1-micro instance运行1个月大约50元人民币,因此用GCE来测试Kubernetes,如果仅是测试时候开启的话,并不会产生太多费用。
Pods及Replication Controller
Kubernetes的基本单元是pods,用来定义一组相关的container。Kubernetes的优点是可以通过定义一个replicationController来将同一个模块部署到任意多个容器中,并且由Kubernetes自动管理。比如定义了一个apache pod,通过replicationController设置启动100个replicas,系统就会在pod创建后自动在所有可用的minions中启动100个apache container。并且轻松的是,当container或者是所在的服务器不可用时,Kubernetes会自动通过启动新的container来保持100个总数不变,这样管理一个大型系统变得轻松和简单。
Service 微服务
在解决部署问题之后,分布式服务中存在的一大难题是服务发现(或者叫寻址),用户访问的前端模块需要访问系统内部的后端资源或者其他各种内部的服务,当一个内部服务通过replicationController动态部署到不同的节点后,而且还存在前文提到的动态切换的功能,前端应用如何来发现并访问这些服务?Kubernetes的另外一个亮点功能就是service,service是一个pod服务池的代理抽象,目前的实现方法是通过一个固定的虚拟IP及端口来定义,并且通过分布在所有节点上的proxy来实现内部服务对service的访问。
Kubernetes自身的配置是保存在一个etcd(类似ZooKeeper)的分布式配置服务中。服务发现为什么不通过etcd来实现?Tim的判断更多的是为了Kubernetes上的系统和具体的配置服务解耦。由于服务发现属于各个系统内部的业务逻辑,因此如果使用etcd将会出现业务代码的逻辑中耦合了etcd,这样可能会让很多架构师望而却步。
尽管没有耦合etcd,部署在Kubernetes中的服务需要通过container中的环境变量来获得service的地址。环境变量虽然简单,但它也存在很多弊端,如存在不方便动态更改等问题。另外service目前的实现是将虚拟IP通过iptables重定向到最终的pod上,作者也提到iptables定向的局限性,不适合作为大型服务(比如上千个内部service一起运作时)的实现。
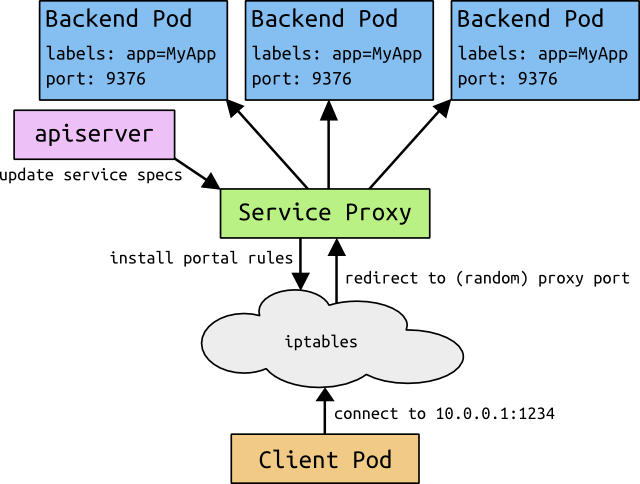
由于service定位是系统内部服务,因此默认情况下虚拟IP无法对外提供服务,但Kubernetes当前版本并没直接提供暴露公网IP及端口的能力,需要借助云服务(比如GCE)的load balancer来实现。
小结
总的看来Kubernetes提供的能力非常令人激动,pod、replicationController以及service的设计非常简单实用。但如果立即将服务迁移到Kubernetes,还需要面对易变的环境。另外尽管Kubernetes提供health check的机制,但service生产环境所需的苛刻的可用性还未得到充分的验证。Service发现尽管不跟Kubernetes的内部实现解耦,但利用环境变量来实现复杂系统的服务发现也存在一些不足。
安装说明
Kubernetes cluster简单安装说明如下,需要尝试的朋友可参考。
前提准备
一个64 bit linux环境,最好在墙外的,避免访问google cloud出现超时或reset等问题;另外创建Google Cloud帐号,确保创建instances以及Cloud Storage功能可用;
安装步骤
1. 安装go语言环境(可选,如果需要编译代码则需要)
2. 安装Google cloud sdk
$ curl https://sdk.cloud.google.com | bash
$ gcloud auth login
按提示完成授权及登录
3. 安装 etcd 二进制版本(V0.4.6), 解压后将其目录加入PATH
4. 安装 kubernetes最新的relase binary版本(V0.5.1)
修改 cluster/gce/config-default.sh,主要是修改以下字段以便节约资源。
MASTER_SIZE=f1-micro MINION_SIZE=f1-micro NUM_MINIONS=3
在kubernetes目录运行
$ cluster/kube-up.sh
执行成功后会显示 done
5. 测试pod
以上脚本启动了examples/monitoring 下面定义的service,如果尝试启动其它自己的pods,比如启动一个tomcat集群
{
"id": "tomcatController",
"kind": "ReplicationController",
"apiVersion": "v1beta1",
"desiredState": {
"replicas": 2,
"replicaSelector":{"name": "tomcatCluster"},
"podTemplate":{
"desiredState": {
"manifest": {
"version": "v1beta1",
"id": "tomcat",
"containers": [{
"name": "tomcat",
"image": "tutum/tomcat",
"ports": [
{"containerPort":8080,"hostPort":80}
]
}]
}
},
"labels": {"name": "tomcatCluster"}}
},
"labels": {
"name": "tomcatCluster",
}
}
其中pod的tomcat image可以通过Docker Hub Registry https://registry.hub.docker.com/ 搜索及获取
$ cluster/kubectl.sh create -f tomcat-pod.json
创建成功后通过 cluster/kubectl.sh get pods 来查看它所在minion及ip,可以通过curl或浏览器来访问(请开启GCE防火墙端口设置)。
再定义一个 service
{
"id": "tomcat",
"kind": "Service",
"apiVersion": "v1beta1",
"port": 8080,
"containerPort": 8080,
"labels": {
"name": "tomcatCluster"
},
"selector": {
"name": "tomcatCluster"
}
}
保存为 tomcat-service.json
$ cluster/kubectl.sh create -f tomcat-service.json
检查service启动后的ip及端口,由于service是内部ip,可以在GCE上通过curl来测试及验证。
$ cluster/kubectl.sh get services
6. 关闭cluster
cluster/kube-down.sh