最近一两年,大部分系统的数据流由基于日志的离线处理方式转变成实时的流式处理方式,并逐渐形成几种通用的使用方式,以下介绍微博的消息队列体系。
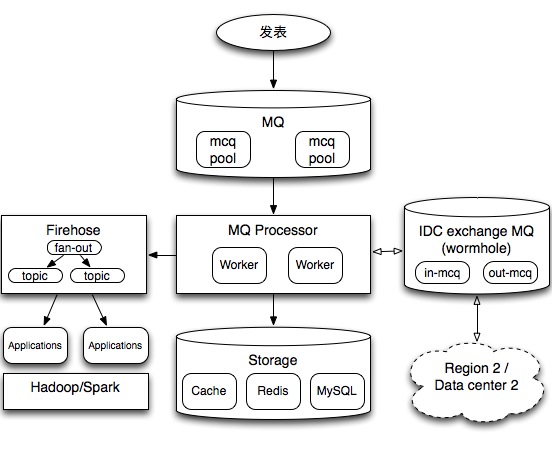
当前的主要消息队列分成如图3部分:
1、feed信息流主流程处理,图中中间的流程,通过相关MQ worker将数据写入cache、Redis及MySQL,以便用户浏览信息流。传统的队列使用主要是为了将操作异步处理,起到削峰填谷的作用,并解除多个序列操作之间的耦合关系。
2、流式计算,图中左边的流程,主要进行大数据相关实时处理。
3、多机房处理,将数据分发到多个机房,由于微博使用了一种多机房数据对等架构,通过消息队列将数据同步到多个机房,因此在每个机房都会有一个类似虫洞这样的消息收发模块IDC exchange MQ。
系统的主要单元
mq:消息队列,新浪的memcacheq,是一种单机的类似redis queue的一个一对一队列系统。
firehose:微博数据统一队列,使用http及memcache协议,由于在业务上每份数据会被多个项目使用,firehose主要用在一对多场景,且支持at-least-once投递保证,类似Apache Kafka。
worker:队列处理程序,自己开发的程序,完成特定的任务如将数据从队列取出入库,类似Apache Storm的bolt。
架构主要特点
实时性:所有的数据在100ms之内处理完成,包括存储型任务。
可扩展性:系统主要单元mq, firehose, worker都是无状态设计,同一个pool每个节点可以处理相同的工作,因此可以线性扩展。
可用性:由于上述的无状态设计,可用性可达 99.999%,自动failover,无单点。
数据流设计特点
统一的数据推送通道 firehose
统一的标准化的格式,所有数据采用内部的protocol buffers格式输出
目前在实时数据流及处理方面存在多种技术,为什么没有采用相关成熟的解决方案?
LinkedIn Databus
LinkedIn databus主要原理是基于数据库变化事件的触发写入一个统一的databus,所有的业务都消费databus,和firehose解决的问题比较类似,不过firehose是业务主动写入的事件,在早期做多机房架构时候也曾经尝试过类似databus数据库触发方案,但在一个高度拆分的数据库场景中,一个业务的操作可能对应多个数据库操作(比如修改索引表和实体表),多个数据库操作并没有严格的时序性。因此基于数据库的变化的事件比较难实时合并成一个完整的业务事件。而通过业务写入事件只需要一个简单的mq操作写入即可,因此在数据库有复杂拆分的场景下,业务独立写入变化事件结构上更简单,也保证了事件本身的原子性。
Storm
Apache Storm是和微博架构同一时间发展的技术,主要对worker的管理抽象成一个框架,支持任务调度,任务容灾,任务多级传递(bolt A处理完后传递给bolt B),数据转换从worker中分离出来变成独立的spout。对于一个复杂且数据源多样的环境,Storm确实具有更好的优势。
Kafka
Apache Kafka是一个分布式的消息队列产品,支持按照partition线性扩展,投递上也默认at-least-once。而图中Firehose是一种面向feed业务的消息服务,同时根据社交关系的特点,还具备根据关系将数据fan-out的能力。
PS:
1、上述内容会在 2014.12.19 ArchSummit Beijing 大数据feed架构演讲中介绍,欢迎参会的同行前来交流。
2、有关大数据及流式计算,可参阅前微博同事张俊林的《大数据日知录》一书。