上文为什么超长列表数据的翻页技术实现复杂提到了超长列表翻页技术设计上一些问题,今天讨论下部分解决思路。
前新浪同事 @pi1ot 最近在程序员杂志发表的一篇文章《门户级UGC系统的技术进化路线》也是超长列表的一个经典案例,在正式展开思路之前,我们也不妨了解一下此文所说新浪评论系统的演进思路。
从文中看到几个版本的列表翻页实现方案
3.0版
3.0系统的缓存模块设计的比较巧妙,以显示页面为单位缓存数据,因为评论页面是依照提交时间降序排列,每新增一条新评论,所有帖子都需要向下移动一位,所以缓存格式设计为每两页数据一个文件,前后相邻的两个文件有一页的数据重复,最新的缓存文件通常情况下不满两页数据。
此方案由于每页的条数是定长的,因此主要采用缓存所有列表的方案。但为了数据更新的便利,缓存结构比较复杂。从今天多年之后的眼光来看,这种设计不利于理解、扩展及维护。因此目前大多不倾向使用这种方案。
4.0版
解决方案是在MySQL数据库和页面缓存模块之间,新建一个带索引的数据文件层,每条新闻的所有评论都单独保存在一个索引文件和一个数据文件中,期望通过把对数据库单一表文件的读写操作,分解为文件系统上互不干涉可并发执行的读写操作,来提高系统并发处理能力。在新的索引数据模块中,查询评论总数、追加评论、更新评论状态都是针对性优化过的高效率操作。从这时候起,MySQL数据库就降到了只提供归档备份和内部管理查询的角色,不再直接承载任何用户更新和查询请求了。
使用自定义索引的方式,由于未与相关人员交流细节,推断应该是类似数组的结构。
从上述案例看到,评论系统是一种典型的超长列表数据结构,如果再MySQL的基础上来做,需要设计额外的索引结构来实现高效的翻页功能。
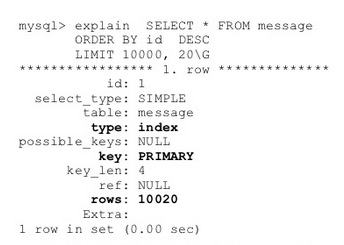
由于超长列表的翻页实现成本高主要是由于列表索引的B-TREE结构方面原因,B-TREE结构能快速查找到某个key,但不是为叶子节点的Range访问而设计,因此主要解决思路也是围绕B-TREE的range访问而进行优化。
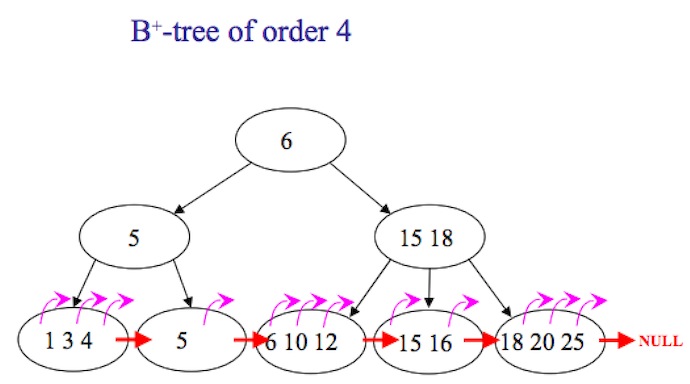
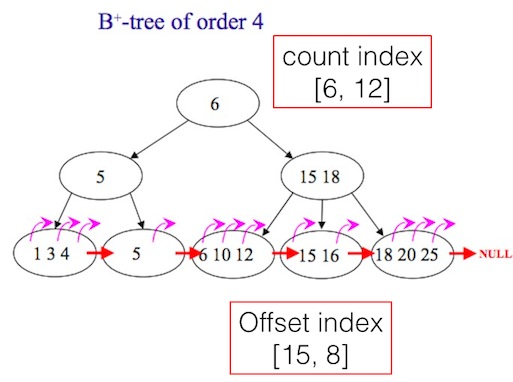
首先、从原理来看,可以在B-TREE增加以下2个二级索引字段:
- Count index 记录每个非叶子节点下的条目数,这样可以帮助快速定位到任意的offset;
- Offset index 记录部分叶子节点的offset,比如每隔1000个id记录一个offset如下,并保存在另外一个列表中,当需要查找某个offset的时候,则可以利用附近已经记录offset的id来定位目的地位置。比如当翻页到1010时,如果offset index记录了[1000: id10345],则可以从id10345往后10个元素找到10010。
[
{"1000":10345},
{"2000":13456},
{"3000":22345},
{"4000":56789},
{"5000":66788}
]
这2个字段可以同时使用,也可以只用其中一个。如图
再看如何将上述方法应用到具体的实现中。由于本文主要讨论MySQL环境,MySQL要在B-TREE上额外保存一些信息需要修改MySQL源代码,修改门槛较高,因此更简单方法是将上述二级索引通过应用层保存在另外的表中。
一种非严格意义的count index实现如下:
CREATE TABLE IF NOT EXISTS `second_index` ( `id` int(11) NOT NULL AUTO_INCREMENT, `uid` int(11) NOT NULL, `yymm` int(11) NOT NULL, `index_count` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `second_index` (`id`, `uid`, `yymm`, `index_count`) VALUES (1, 1, 1409, 123), (2, 1, 1410, 2342), (3, 1, 1411, 534), (4, 1, 1412, 784), (5, 1, 1501, 845);
一种offset index实现如下:
在第一次用户翻页到某个offset位置时,在redis直接保存offset, id。当有其他请求来查找offset之后数据时,可以从offset的位置往后扫描。如果列表的数据发生了变化,需要及时将Redis保存的offset index删除。
以上2种方法已经在生产环境使用。
@icycrystal4对此文所提方法亦有贡献。