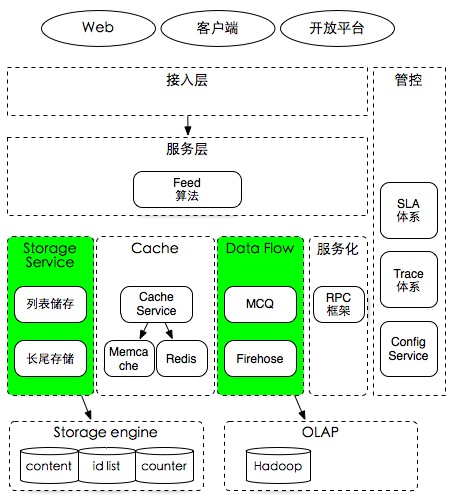
虽然春节已经过去一段时间,但不少微信群里面依旧乐此不疲的在玩发红包活动,用户自发的将最初的一个春节拜年的场景功能慢慢演化成一个长尾功能。
用户在微信中抢红包时分成抢包和拆包两个操作。抢包决定红包是否还有剩余金额,但如果行动不够迅速,在拆包阶段可能红包已经被其他用户抢走的情况。
红包的金额是在什么时候算? 据某架构群腾讯财付通专家反馈,红包的金额是拆的时候实时计算,而不是预先分配,实时计算基于内存,不需要额外存储空间,并且实时计算效率也很高。每次拆红包时,系统取0.01到剩余平均值*2之间作为红包的金额。
为了保证每次操作的原子性,拆包过程中使用了CAS,确保每次只有一个并发用户拆包成功。拆包CAS失败的用户可以由系统自动进行重试。但也有可能在重试过程中被别的用户抢得先机而空手而归,因此严格意义拆包的调用也未能保证用户先到先得。
基于上面的原因,当时在群中提到这种算法有些复杂,微信红包为了减少存储,每次进行了一个理解稍复杂的实时计算。对比大部分架构师想到的预分配金额的做法,预先分配金额需要将金额保存在一个内存队列中,如果红包的份额较多,则需要较大的存储空间。而微信红包仅保存 count:balance 这样2个数字。count指还剩几个人可以抢,balance只还剩下的金额。
但是预分配金额也并不是非得需要额外存储。比如利用随机算法,在种子相同的情况下,随机数实际上返回的随机序列也是固定的。如以下Python代码,对于给定的seed 1024,每次执行返回的结果都是相同的。
>>> import random
>>> random.seed(1024)
>>> random.randint(1,100)
80
>>> random.randint(1,100)
49
>>> random.randint(1,100)
39
>>> random.randint(1,100)
83
>>> random.randint(1,100)
88
因此预分配金额也只需要额外存储一个种子,或利用一些红包id做加密变换做seed达到零存储。而在发放红包时候,无需进行CAS操作,而只需要对剩余红包count做一个DECR操作。当count<0时,表示红包被拆包抢完。由于DECR是原子操作,无需加锁,用简单的方法达到了先拆包先得,原理上不存在早拆包但由于并发冲突失败而抢不到红包的情况。 每个人分配的金额是:total * random(n) / random_total,不需要重复计算。 random(1)..random(n)不需要保存,因为对于给定的seed,random(1)到random(n)返回是固定的。 以上算法评论与对比,与Tim所在雇主的红包算法无关,特此声明。
部分细节下面列表已做说明,未做详细阐述。
Reference:
1、微信红包的架构设计简介
2、网友周航老师基于聊天记录整理的微信红包架构图(点击查看大图)

3、微信红包实现原理
对于上文中提到的架构群感兴趣的朋友可以关注Tim公众号“TimYang_net”后回复“arch”获取进群方式。