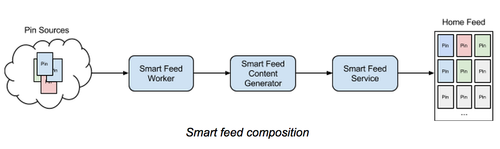
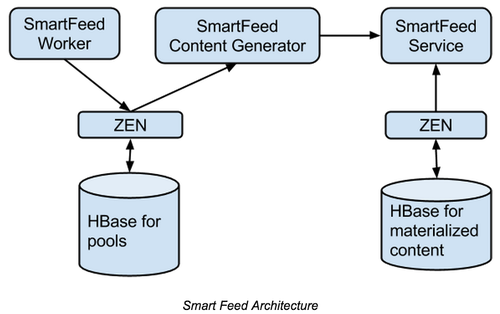
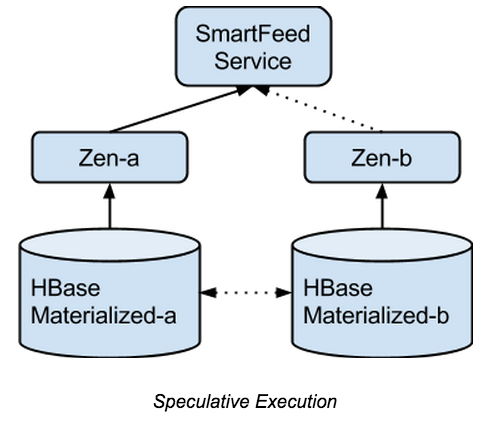
上文为什么我认为架构师需要坚持写代码发出后,看到一个朋友在网上分享了他最近的变化,经过深思熟虑,这位朋友已经离职放弃了原来舒适但是不太需要技术驱动的位置,去重新寻找让自己更有激情、能更好体现技术价值的环境及平台。
最近阅读的《硅谷之谜》中,吴军也将工程师分成五个等级
第五等工程师 独立完成任务
第四等工程师 领导产品
第三等工程师 行业最优
第二等工程师 改变世界
第一等工程师 开创行业
这跟上文提到的架构师的分类方法比较类似。第五等工程师是指能够独立完成功能模块的人,第四等需要具有产品的意识以及能够带领及组织公司资源完成某项产品的开发。第五等和第四等其实都任务导向型。而更高的几种类型则需要善用技术及平台的力量。
第三等工程师可以做出行业最好的产品,吴军讲到这类人与第二类的差异是这一类人需要“悟性”,当然也需要后天因素,比如处于一个上升平台的舞台上。
即使一个人再聪明,基础再好,也需要在工程上花足够的时间才能达到这个水平,一个年轻人工作四五年就开始做行政管理工作,基本就和这个水平无缘了。
第二等及第一等则是能充分利用技术力量改变世界的人,吴军更多的是从产品及结果导向来看归类这两类人,比如 iPhone 总设计师、爱迪生等人。
硅谷的介绍虽然过度开采,但在工程师眼里却一直充满着永久的好奇与热情。每年都有大量技术从业人员去硅谷游学研修,了解地球另外一边的一群人,是通过怎么样的组织方式,利用技术创新来改变世界。
因此可以通过吴军在《硅谷之谜》中的角度,来了解硅谷的工程师是如何样通过技术来体现自己的价值。
在另外一些内容介绍硅谷公司对于工程师代码的要求,也多次提到代码能力的重要性。一些具有较好业界名气、或者具备丰富经验的人员,进入一些知名互联网公司之前也需要测试基本的代码能力,而如果不能通过的话则无法通过面试。
在硅谷的公司里,从录取开始就显示出对权威和经验的一种淡漠。在 Google,不管面试者名气多大,水平多高,过不了一关关的面试也是白搭。对于那些技术负责人职位的申请者,不论申请者年龄多大,过去的经验多么丰富,一定要考技术问题,甚至包括写程序。因此,一个有名气有经验的申请者,未必比那些大学刚毕业的人更容易被录用。我曾经遇到这样一个例子,一个在美国顶级计算机系工作的教授,先推荐了他的两个学生来 Google 应聘,结果都录用了。后来他自己来应聘,Google 要他做他的学生做过的类似的考题,他反而没有考过,虽然我们很为他感到可惜,但是也没有办法。这位教授很不服气,对我讲,我的学生远不如我你们却要了,我发表过那么多论文,拿到过那么多基金你们却不要,说明你们的眼光有问题。我承认他讲的很有道理,但是,不能为一个人坏了规矩。类似的情况在 Facebook 也发生过,某公司的一位工程总监手底下的好几个人都被 Facebook 录用了,等到他自己去,因为编程荒疏,反而被拒绝了。
另外一些正向的例子也提到一些行业泰斗坚持工作在技术一线。
在硅谷你总是能看到一些世界科技行业的泰斗或巨头还在写程序。Google 的狄恩(Jeff Dean)和戈玛瓦特(Sanjay Ghemawat)是世界上最早发明云计算技术的工程师,也都是美国工程院院士,至今仍在自己写代码,而且每次有什么新的想法,都是自己先实现自己的狗食(Dogfood)。Google 的汤普森是 Unix 的发明人,图灵奖的获得者,每天大部分时间仍然花在写程序上。太阳工作站的发明人,该公司的创始人贝托谢姆,后来成为了天使投资人,又投资成立了上市公司 Arista,今天仍然在写程序。这些人可算是功成名就,要是放在中国,早就当官去了,至少也进入了到“君子动口不动手”的状态,但是他们在硅谷依然自己动手。虽然他们自己写的代码未必比别人好多少,但是这在硅谷营造了自己动手的工程师文化。
在硅谷之谜中,多次提到硅谷影响最大的红杉资本。12 月 5 日,在中国企业领袖年会上,红杉资本全球执行合伙人沈南鹏就创新创业的下一站——科技创新主题发表了类似观点。
“全球性”公司必须有一个重要的特征,产品上一定是科技的创新,而不仅仅是模式的创新。我们相信在今天新一代的创业者,很多有国际化的视野,也有国际化的工作经验包括科技研发的经验,他们一定会引领中国下一个风口,这样的创业创新一定会产生一批有全球竞争力的优秀企业。